In my previous article "Install Lagopus software switch on Ubuntu 12.04", the virtual switch, Lagopus just heavily leverage DPDK to enhance the line rate near to the physical NIC capacity. Recently I saw an article "Scaling NFV to 213 Million Packets per Second with Red Hat Enterprise Linux, OpenStack, and DPDK", which mentions using DPDK in OpenStack and test its performance in RedHat Enterprise. Again DPDK is adopted in the network virtualization under OpenStack. Even thought there are some hardware specification limitation, for instance, with Intel x86 CPU and some series of network ethernet cards. But, I believe it will become one of standard option, just like SR-IOV, to deploy OpenStack in the future.
If you want to get started OpenStack with DPDK, I suggest to study Open vSwitch with DPDK first because the networking of virtual machines are all related with Open vSwitch.
https://github.com/openvswitch/ovs/blob/master/INSTALL.DPDK.md
Here are more related information for reference:
Accelerating Neutron with Intel DPDK
http://www.slideshare.net/AlexanderShalimov/ashalimov-neutron-dpdkv1
Intel DPDK Step by Step instructions
http://www.slideshare.net/hisaki/intel-dpdk-step-by-step-instructions
git: stackforge/networking-ovs-dpdk
http://git.openstack.org/cgit/stackforge/networking-ovs-dpdk
Thursday, August 27, 2015
Friday, August 21, 2015
[Shell] ShellEd, the Shell Script Editor for Eclipse
If someone wants to use shell script editor in Eclipse, I think ShellEd is good candidate and its provides features, like syntax highlighting. The installation steps are here:
go Help => install new software => Add
Name: ShellEd
Location: http://www.chasetechnology.co.uk/eclipse/updates
Friday, August 7, 2015
[Docker] What is the difference between Docker and LXC?
As we know Docker is a hot topic in recent cloud conference or summit, for instance, OpenStack. Google also announced that they will donate its open source project "Kubernets" and integrate it into OpenStack. The news definitely cheers up a lot of OpenStackers. For me, I use LXC before, but don't know too much about Docker. So, I am curious the difference between Docker and LXC. Here it is:
https://www.flockport.com/lxc-vs-docker/
 This content in the URL gives me the answer for my question.
This content in the URL gives me the answer for my question.
http://stackoverflow.com/questions/17989306/what-does-docker-add-to-lxc-tools-the-userspace-lxc-tools
Reference:
Docker in technical details ( Chinese Version)
http://www.cnblogs.com/feisky/p/4105739.html
https://www.flockport.com/lxc-vs-docker/
http://stackoverflow.com/questions/17989306/what-does-docker-add-to-lxc-tools-the-userspace-lxc-tools
Docker is not a replacement for lxc. "lxc" refers to capabilities of the linux kernel (specifically namespaces and control groups) which allow sandboxing processes from one another, and controlling their resource allocations.
On top of this low-level foundation of kernel features, Docker offers a high-level tool with several powerful functionalities:
- Portable deployment across machines. Docker defines a format for bundling an application and all its dependencies into a single object which can be transferred to any docker-enabled machine, and executed there with the guarantee that the execution environment exposed to the application will be the same. Lxc implements process sandboxing, which is an important pre-requisite for portable deployment, but that alone is not enough for portable deployment. If you sent me a copy of your application installed in a custom lxc configuration, it would almost certainly not run on my machine the way it does on yours, because it is tied to your machine's specific configuration: networking, storage, logging, distro, etc. Docker defines an abstraction for these machine-specific settings, so that the exact same docker container can run - unchanged - on many different machines, with many different configurations.
- Application-centric. Docker is optimized for the deployment of applications, as opposed to machines. This is reflected in its API, user interface, design philosophy and documentation. By contrast, the lxc helper scripts focus on containers as lightweight machines - basically servers that boot faster and need less ram. We think there's more to containers than just that.
- Automatic build. Docker includes a tool for developers to automatically assemble a container from their source code, with full control over application dependencies, build tools, packaging etc. They are free to use make, maven, chef, puppet, salt, debian packages, rpms, source tarballs, or any combination of the above, regardless of the configuration of the machines.
- Versioning. Docker includes git-like capabilities for tracking successive versions of a container, inspecting the diff between versions, committing new versions, rolling back etc. The history also includes how a container was assembled and by whom, so you get full traceability from the production server all the way back to the upstream developer. Docker also implements incremental uploads and downloads, similar to "git pull", so new versions of a container can be transferred by only sending diffs.
- Component re-use. Any container can be used as an "base image" to create more specialized components. This can be done manually or as part of an automated build. For example you can prepare the ideal python environment, and use it as a base for 10 different applications. Your ideal postgresql setup can be re-used for all your future projects. And so on.
- Sharing. Docker has access to a public registry (https://registry.hub.docker.com/) where thousands of people have uploaded useful containers: anything from redis, couchdb, postgres to irc bouncers to rails app servers to hadoop to base images for various distros. The registry also includes an official "standard library" of useful containers maintained by the docker team. The registry itself is open-source, so anyone can deploy their own registry to store and transfer private containers, for internal server deployments for example.
- Tool ecosystem. Docker defines an API for automating and customizing the creation and deployment of containers. There are a huge number of tools integrating with docker to extend its capabilities. PaaS-like deployment (Dokku, Deis, Flynn), multi-node orchestration (maestro, salt, mesos, openstack nova), management dashboards (docker-ui, openstack horizon, shipyard), configuration management (chef, puppet), continuous integration (jenkins, strider, travis), etc. Docker is rapidly establishing itself as the standard for container-based tooling.
Reference:
Docker in technical details ( Chinese Version)
http://www.cnblogs.com/feisky/p/4105739.html
Monday, August 3, 2015
[Raspberry Pi] What job do I use my Pi to do?
I bought my Raspberry Pi last year and didn't use it often. The main reason is that I didn't figure out what job I use my Pi to do. Until several months ago, I finally made the decision: My Pi will become a torrent server... Nice.

There is a very good advantage to use Pi to act as torrent server: "low power consumption"
So, here is the steps to do:
http://www.takobear.tw/2014/12/07/rpiraspberry-pibt-2/
http://www.takobear.tw/2014/03/20/rpiraspberry-pibt/

P.S: This web site also has a lot of tutorials for Raspberry Pi, check it out: http://www.takobear.tw/category/tutorial/rpi/

So, here is the steps to do:
http://www.takobear.tw/2014/12/07/rpiraspberry-pibt-2/
http://www.takobear.tw/2014/03/20/rpiraspberry-pibt/

P.S: This web site also has a lot of tutorials for Raspberry Pi, check it out: http://www.takobear.tw/category/tutorial/rpi/
[Linux] “No such file or directory” on files that exist?
First, this kind of problem is almost related with dynamic loader. You can check out what it is:
To understand Linux Dynamic Loader
http://www.cs.virginia.edu/~dww4s/articles/ld_linux.html
After verifying it with several ways:
# file "your binary"
# readelf -l "your binary"
# strings "your binary" | grep ld-
Then you can find out which dynamic loader your binary uses.
For my case, I just create a symbolic link to my loader, and then it works.
I also find some other issue about running a 32-bit binary on a 64-bit system. Here is a good answer in the following link:
Quote:
"But the program is a 32-bit program (as the
http://unix.stackexchange.com/questions/13391/getting-not-found-message-when-running-a-32-bit-binary-on-a-64-bit-system
To install ia32-libs on debian wheezy amd64:
To understand Linux Dynamic Loader
http://www.cs.virginia.edu/~dww4s/articles/ld_linux.html
After verifying it with several ways:
# file "your binary"
# readelf -l "your binary"
# strings "your binary" | grep ld-
Then you can find out which dynamic loader your binary uses.
For my case, I just create a symbolic link to my loader, and then it works.
liudanny@Debian7 x64_lsb $ ll /lib64/
total 8
drwxr-xr-x 2 root root 4096 Aug 2 20:49 .
drwxr-xr-x 24 root root 4096 Jun 20 18:14 ..
lrwxrwxrwx 1 root root 32 Feb 22 06:41 ld-linux-x86-64.so.2 -> /lib/x86_64-linux-gnu/ld-2.13.so
lrwxrwxrwx 1 root root 20 Aug 2 20:49 ld-lsb-x86-64.so.3 -> ld-linux-x86-64.so.2I also find some other issue about running a 32-bit binary on a 64-bit system. Here is a good answer in the following link:
Quote:
"But the program is a 32-bit program (as the
file output indicates), looking for the 32-bit loader /lib/ld-linux.so.2, and you've presumably only installed the 64-bit loader /lib64/ld-linux-x86-64.so.2 in the chroot."http://unix.stackexchange.com/questions/13391/getting-not-found-message-when-running-a-32-bit-binary-on-a-64-bit-system
To install ia32-libs on debian wheezy amd64:
dpkg --add-architecture i386
apt-get update
apt-get install libc6:i386sudo dpkg --add-architecture i386
sudo apt-get update
sudo aptitude install ia32-libsWednesday, July 29, 2015
[Python] Effective Python
Two weeks ago, my friend discussed the best practice for Django and Python in programming.
After that for a while, one day I just came up with a idea: I read a book "Effective C++" and why not there is a book about "Effective Python"? So, here it is: http://www.effectivepython.com/
I wish I can find some time to walk through this book.

After that for a while, one day I just came up with a idea: I read a book "Effective C++" and why not there is a book about "Effective Python"? So, here it is: http://www.effectivepython.com/
I wish I can find some time to walk through this book.

Monday, July 27, 2015
[Neutron] Slow network speed between VM and external
Recently I encountered a situation of the VM's network performance that is pretty low. For instance, if upload a image to Glance via my VM to run glance cli command, the actual transmit speed is around the following data:
They talked about the approach on the VM to solve the issue and this works
But, for my case I think it is notsolve from the root cause so that I take time to do the research for TCP segmentation offload and GRE. Finally I find the root cause:
MTU need to adjust when usingGRE network service .
http://docs.openstack.org/juno/install-guide/install/yum/content/neutron-network-node.html
Quote:
"Tunneling protocols such as GRE include additional packet headers that increase overhead and decreasespace available for the payload or user data. Without knowledge of the virtual network infrastructure, instances attempt to send packets using the default Ethernet maximum transmission unit (MTU) of 1500 bytes.Internet protocol (IP) networks contain the path MTU discovery (PMTUD) mechanism to detect end-to-end MTU and adjust packet size accordingly. However, some operating systems and networks block or otherwise lack support for PMTUD causing performance degradation or connectivity failure.
Ideally, you can prevent these problems by enabling jumbo frames on the physical network that contains your tenant virtual networks. Jumbo frames support MTUs up to approximately 9000 bytes which negates the impact of GRE overhead on virtual networks. However, many network devices lack support for jumbo frames and OpenStack administrators often lack control over network infrastructure. Given the latter complications, you can also prevent MTU problems by reducing the instance MTU to account for GRE overhead. Determining the proper MTU value often takes experimentation, but 1454 bytes works in most environments. You can configure the DHCP server that assigns IP addresses to your instances to also adjust the MTU."
After doing the following setting on Controller node, the transmit speed is up to:
So, the network performance is improved 200 times.
Wow...
Reference:
TCP segmentation offload
https://forum.ivorde.com/linux-tso-tcp-segmentation-offload-what-it-means-and-how-to-enable-disable-it-t19721.html
TCP in Linux Kernel
http://vger.kernel.org/~davem/tcp_output.html
Understanding TCP Segmentation Offload (TSO) and Large Receive Offload (LRO) in a VMware environmenthttps://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2055140
RX: 130 Kbps
TX: 150 Kbps
My OpenStack's network service is with GRE segmentation on Neutron. Why? After google the web, I found some people had the same issues as I had:
They talked about the approach on the VM to solve the issue and this works
> ethtool -K eth0 gro off
> ethtool -K eth0 tso off
But, for my case I think it is not
MTU need to adjust when using
http://docs.openstack.org/juno/install-guide/install/yum/content/neutron-network-node.html
Quote:
"Tunneling protocols such as GRE include additional packet headers that increase overhead and decrease
Ideally, you can prevent these problems by enabling jumbo frames on the physical network that contains your tenant virtual networks. Jumbo frames support MTUs up to approximately 9000 bytes which negates the impact of GRE overhead on virtual networks. However, many network devices lack support for jumbo frames and OpenStack administrators often lack control over network infrastructure. Given the latter complications, you can also prevent MTU prob
After doing the following setting on Controller node, the transmit speed is up to:
RX: 31323 Kbps
TX: 31464 Kbps
- Edit the
/etc/neutron/dhcp_agent.inifile and complete the following action:- In the
[DEFAULT]section, enable the dnsmasq configuration file:123[DEFAULT]...dnsmasq_config_file =/etc/neutron/dnsmasq-neutron.conf
- Create and edit the
/etc/neutron/dnsmasq-neutron.conffile and complete the following action:- Enable the DHCP MTU option (26) and configure it to 1454 bytes:1
dhcp-option-force=26,1454
- Kill any existing
dnsmasqprocesses:# pkill dnsmasq
So, the network performance is improved 200 times.
Wow...
Reference:
TCP segmentation offload
https://forum.ivorde.com/linux-tso-tcp-segmentation-offload-what-it-means-and-how-to-enable-disable-it-t19721.html
TCP in Linux Kernel
http://vger.kernel.org/~davem/tcp_output.html
Understanding TCP Segmentation Offload (TSO) and Large Receive Offload (LRO) in a VMware environmenthttps://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2055140
Monday, June 8, 2015
[OF-DPA] A simple L2 switch RYU app for OF-DPA
I found there is a official OF-DPA web site that contains some good information about RYU and OF-DPA as follows:
http://ofdpa.com/
I also put my simple L2 switch RYU app for OF-DPA which I had done an example in the last year and cannot guarantee there is no error/bug. But, it is still worth referencing. Enjoy.
Here it is:
https://github.com/teyenliu/OF-DPA
http://ofdpa.com/
I also put my simple L2 switch RYU app for OF-DPA which I had done an example in the last year and cannot guarantee there is no error/bug. But, it is still worth referencing. Enjoy.
Here it is:
https://github.com/teyenliu/OF-DPA
Wednesday, May 20, 2015
[GIT] The git commands that I often use
I just list the git commands that I often use and keep in this document
//pull
git
//check
git
//apply diff
git apply diff
// Check thediff
git diff
//code commit
git commit -a -m "This is bug
//push commit
git push "your remote site" "your branch"
//repository
git remote rm origin
git remote add origin git@...git
git remote set-url origin git@...git
//add
git remote add "remote repository name" ssh:
//Force to go back the current newest commit
git reset --hard HEAD
HEAD^ // the previous commit
HEAD~2 // the previous two commit
git reset --hard eb2b844 // the previous a commit with your hash code
--soft stage
--hard
//cancel
git checkout -- <file>
//modify
git commit --amend
//reset some
git reset
//reset
git reset
//clean
git cleanup -f
//checkout
git checkout "branch"
//checkout new branch track
git checkout -t -b bcm bcm
//look
git log
//cherry
git cherry-pick "hash code"
//push remote repository
git push remote repository name
//use diff
gitk
//merge
git merge "branch"
// There are severalmergetools
// I suggest to use p4merge/meld
//the difftool diff
git difftool -t p4merge aa202d3..be15911907d9 -- *.cc
git mergetool -t p4merge myfile.cc
//keep
git stash
//check
git stash list
//apply
git stash apply --index
//to
git stash pop
//create
git stash branch "your stash branch name"
// Undo a commit and redo
git commit ...
git reset --soft HEAD~1 (2)
<<edit
git add ....
git commit -c ORIG_HEAD (5)
// Remove all . pyc . xxx files
find . name . pyc
// Remove a file inremote repository
git rm --cached your_file_here
// Setignore file
git config --global core. excludesfile ~/. gitignore_global
// Ignore SSL verification
env
or
git config http . sslVerify
// Get sources aftercommit
git checkout 336e1731fd8591c712d029681392e5982b2c7e6b src abc
// *** Avoiding annoying merge commits:
git pull --rebase origin master
git pull --rebase origin
// Avoiding to merge or commit yourcustomised configs
git update-index --assume-unchanged [filepath
// Putting back and tracking the files above:
git update-index --no-assume-unchanged [filepath
//
//
//
// Check the
//
//
//
//
//Force to go back the current newest commit
HEAD^ // the previous commit
HEAD~2 // the previous two commit
--
--
//
//
//
//
//
//
//
//
//
//
//
//
// There are several
// I suggest to use p4merge/meld
//
git difftool -t p4merge aa202d3..be15911907d9 -- *.cc
git mergetool -t p4merge myfile.cc
//
//
//
//
//
// Undo a commit and redo
<<
// Remove all
// Remove a file in
// Set
// Ignore SSL verification
// Get sources after
// *** Avoiding annoying merge commits:
git pull --rebase origin
// Avoiding to merge or commit your
// Putting back and tracking the files above:
Tuesday, May 12, 2015
[Django] The summary of "Writing your first Django app" in offical Django document
Well, if we want to really get understanding something, the best way is to study and do by yourself. The official Django web site gives us a very good example for those who are the first time to use Django. So this article is just the quick summary of this "Writing your first Django app" as follows:
Writing your first Django app, part 1
Writing your first Django app, part 2
Writing your first Django app, part 3
Writing your first Django app, part 4
Writing your first Django app, part 5
Writing your first Django app, part 6
Advanced tutorial: How to write reusable apps
$ django-admin startproject r300
$ python -m django --version
$ python -c "import django; print(django.get_version())"
$ django-admin startproject R300
$ python manage.py startapp demo
$ python manage.py migrate
$ python manage.py runserver 0.0.0.0:8000
After finishing the above steps, we can get the file structure like the picture below:

This picture is about the polls application that looks like:
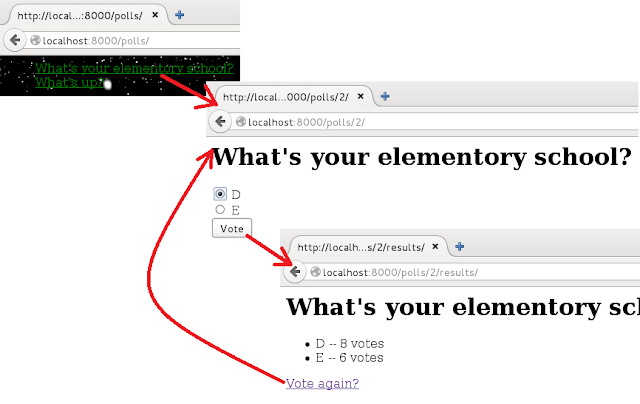
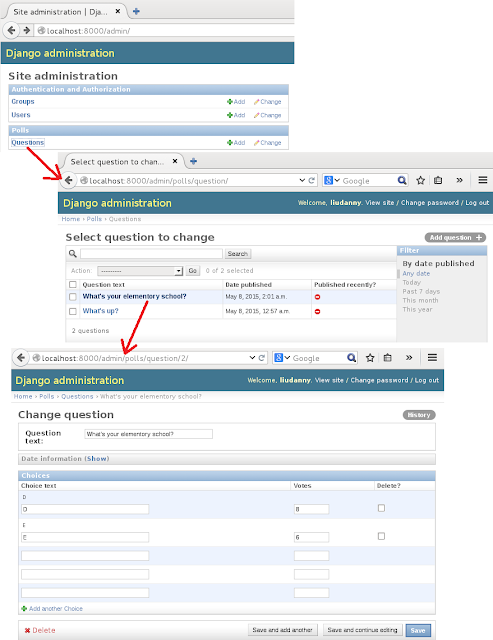
And this picture is about the admin application that is to manage polls data:
If you want to deploy this polls application to Apache web server with mod_wsgi module, please follow the previous article to install Apache and mod_wsgi. Then, we need to add the setting of /etc/apache2/site-available/default is as follows:

But, in this case, I have not resolved the permission for database and admin application. So, hope to fix these later.
P.S:
There is a very good django e-book as follows:
http://www.djangobook.com/en/2.0/index.html
Writing your first Django app, part 1
Writing your first Django app, part 2
Writing your first Django app, part 3
Writing your first Django app, part 4
Writing your first Django app, part 5
Writing your first Django app, part 6
Advanced tutorial: How to write reusable apps
$ django-admin startproject r300
$ python -m django --version
$ python -c "import django; print(django.get_version())"
$ django-admin startproject R300
$ python manage.py startapp demo
$ python manage.py migrate
$ python manage.py runserver 0.0.0.0:8000
After finishing the above steps, we can get the file structure like the picture below:

This picture is about the polls application that looks like:

And this picture is about the admin application that is to manage polls data:

If you want to deploy this polls application to Apache web server with mod_wsgi module, please follow the previous article to install Apache and mod_wsgi. Then, we need to add the setting of /etc/apache2/site-available/default is as follows:

But, in this case, I have not resolved the permission for database and admin application. So, hope to fix these later.
P.S:
There is a very good django e-book as follows:
http://www.djangobook.com/en/2.0/index.html
Subscribe to:
Posts (Atom)