http://caffe.berkeleyvision.org/doxygen/classcaffe_1_1EuclideanLossLayer.html#details
"This can be used for least-squares regression tasks. An InnerProductLayer input to a EuclideanLossLayer exactly formulates a linear least squares regression problem. With non-zero weight decay the problem becomes one of ridge regression – see src/caffe/test/test_sgd_solver.cpp for a concrete example wherein we check that the gradients computed for a Net with exactly this structure match hand-computed gradient formulas for ridge regression.
(Note: Caffe, and SGD in general, is certainly not the best way to solve linear least squares problems! We use it only as an instructive example.)"
I found a very good example and forked it from regression_problem. I also fixed some bugs so that it can be executed through the whole steps.
Here is my forked repository: https://github.com/teyenliu/dlcv_for_beginners/tree/master/chap9
Please refer to the following net example. The final layer is a EuclideanLossLayer which take the bottom blobs of "pred" and "fred" as input and calculate its loss for further backpropagation process.
name: "RegressionExample" layer { name: "data" type: "HDF5Data" top: "data" top: "freq" include { phase: TRAIN } hdf5_data_param { source: "train_h5.txt" batch_size: 50 } } layer { name: "data" type: "HDF5Data" top: "data" top: "freq" include { phase: TEST } hdf5_data_param { source: "val_h5.txt" batch_size: 50 } } layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 1 decay_mult: 0 } convolution_param { num_output: 96 kernel_size: 5 stride: 2 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" } layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 1 decay_mult: 0 } convolution_param { num_output: 96 pad: 2 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" } layer { name: "pool2" type: "Pooling" bottom: "conv2" top: "pool2" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "conv3" type: "Convolution" bottom: "pool2" top: "conv3" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 1 decay_mult: 0 } convolution_param { num_output: 128 pad: 1 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" } layer { name: "pool3" type: "Pooling" bottom: "conv3" top: "pool3" pooling_param { pool: MAX kernel_size: 3 stride: 2 } } layer { name: "fc4" type: "InnerProduct" bottom: "pool3" top: "fc4" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 1 decay_mult: 0 } inner_product_param { num_output: 192 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 0 } } } layer { name: "relu4" type: "ReLU" bottom: "fc4" top: "fc4" } layer { name: "drop4" type: "Dropout" bottom: "fc4" top: "fc4" dropout_param { dropout_ratio: 0.35 } } layer { name: "fc5" type: "InnerProduct" bottom: "fc4" top: "fc5" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 1 decay_mult: 0 } inner_product_param { num_output: 2 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 0 } } } layer { name: "sigmoid5" type: "Sigmoid" bottom: "fc5" top: "pred" } layer { name: "loss" type: "EuclideanLoss" bottom: "pred" bottom: "freq" top: "loss" }
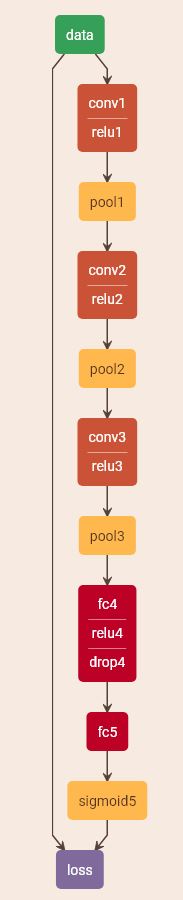
P.S: Sometimes we don't need Sigmoid Layer to wrap the output of InnerProductLayer because we want to get the real value from Neural Network. If so, we can directly connect EuclideanLossLayer to InnerProductLayer without Sigmoid Layer like this:
... ... layer { name: "fc5" type: "InnerProduct" bottom: "fc4" top: "pred" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 1 decay_mult: 0 } inner_product_param { num_output: 2 weight_filler { type: "gaussian" std: 0.005 } bias_filler { type: "constant" value: 0 } } }layer { name: "sigmoid5" type: "Sigmoid" bottom: "fc5" top: "pred" }layer { name: "loss" type: "EuclideanLoss" bottom: "pred" bottom: "freq" top: "loss" }
No comments:
Post a Comment