I got a Jetson TX2 several days ago from my friend and it looks like following pictures. I setup it using Nivida's installing tool: JetPack-L4T-3.2 version (JetPack-L4T-3.2-linux-x64_b196.run). During the installation, I indeed encounter some issues with not abling to setup IP address on TX2, and I resolved it. If anyone still has this issue, let me know and I will post another article to explain the resolving steps.
Thursday, June 7, 2018
Wednesday, August 30, 2017
[Caffe] Try out Caffe with Python code
This document is just a testing record to try out on Caffe with Python code. I refer to this blog. For using Python, we can easily to access every data flow blob in layers, including diff blob, weight blob and bias blob. It is so convenient for us to understand the change of training phase's weights and what have done in each step.
Monday, August 7, 2017
[Caffe] How to use Caffe to solve the regression problem?
There is a question coming up to my mind recently. How to use Caffe to solve the regression problem? We used to see a bunch of examples related to image recognition with labels and they are classification problem. In my experience, I have done this problem using TensorFlow, not Caffe. But, I think in theory they are both the same. The key point is using EuclideanLossLayer as the final Loss Layer and it's the detail from the official web site:
Wednesday, August 2, 2017
[Raspberry Pi] Use Wireless and Ethernet together
The following content is my Raspberry Pi 3's setting in /etc/network/interface as follows. In my case, I both use wireless and ethernet device at the same time.
# Include files from /etc/network/interfaces.d:
source-directory /etc/network/interfaces.d
auto lo
iface lo inet loopback
auto wlan0
allow-hotplug wlan0
iface wlan0 inet manual
Wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
allow-hotplug eth0
iface eth0 inet static
address 140.96.29.224
netmask 255.255.255.0
up ip route add 100.85.0.0/24 via 140.96.29.254 dev eth0
up ip route add 140.96.29.0/24 via 140.96.29.254 dev eth0
up ip route add 140.96.98.0/24 via 140.96.29.254 dev eth0[Debug] Debugging Python and C++ exposed by boost together
During the studying of Caffe, I was curious about how Caffe provides Python interface and what kind of tool uses for wrapping. Then, the answer is Boost.Python. I think for C++ developer, it is worth time to learn and I will study it sooner. In this post, I want to introduce the debugging skill which I found in this post and I believe these are very useful such as debugging Caffe with Python Layer. Here is the link:
https://stackoverflow.com/questions/38898459/debugging-python-and-c-exposed-by-boost-together
https://stackoverflow.com/questions/38898459/debugging-python-and-c-exposed-by-boost-together
Tuesday, July 18, 2017
[PCIe] lspci command and the PCIe devices in my server
The following content is about my PCIe devices/drivers and the lspci command results.
$ cd /sys/bus/pci_express/drivers
$ ls -al
drwxr-xr-x 2 root root 0 7月 6 15:33 aer/
drwxr-xr-x 2 root root 0 7月 6 15:33 pciehp/
drwxr-xr-x 2 root root 0 7月 6 15:33 pcie_pme/
Thursday, May 18, 2017
[Caffe] Install Caffe and the depended packages
This article is just for me to quickly record the all the steps to install the depended packages for Caffe. So, be careful that it maybe is not good for you to walk through them in your environment. ^_^
# Install CCMAKE
$ sudo apt-get install cmake-curses-guiMonday, May 15, 2017
[NCCL] Build and run the test of NCCL
NCCL requires at least CUDA 7.0 and Kepler or newer GPUs. Best performance is achieved when all GPUs are located on a common PCIe root complex, but multi-socket configurations are also supported.
Note: NCCL may also work with CUDA 6.5, but this is an untested configuration.
Build & run
To build the library and tests.$ cd nccl
$ make CUDA_HOME=<cuda install path> test
Test binaries are located in the subdirectories nccl/build/test/{single,mpi}.
$ ~/git/nccl$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./build/lib
$ ~/git/nccl$ ./build/test/single/all_reduce_test 100000000
# Using devices
# Rank 0 uses device 0 [0x04] GeForce GTX 1080 Ti
# Rank 1 uses device 1 [0x05] GeForce GTX 1080 Ti
# Rank 2 uses device 2 [0x08] GeForce GTX 1080 Ti
# Rank 3 uses device 3 [0x09] GeForce GTX 1080 Ti
# Rank 4 uses device 4 [0x83] GeForce GTX 1080 Ti
# Rank 5 uses device 5 [0x84] GeForce GTX 1080 Ti
# Rank 6 uses device 6 [0x87] GeForce GTX 1080 Ti
# Rank 7 uses device 7 [0x88] GeForce GTX 1080 Ti
# out-of-place in-place
# bytes N type op time algbw busbw res time algbw busbw res
100000000 100000000 char sum 30.244 3.31 5.79 0e+00 29.892 3.35 5.85 0e+00
100000000 100000000 char prod 30.493 3.28 5.74 0e+00 30.524 3.28 5.73 0e+00
100000000 100000000 char max 29.745 3.36 5.88 0e+00 29.877 3.35 5.86 0e+00
100000000 100000000 char min 29.744 3.36 5.88 0e+00 29.868 3.35 5.86 0e+00
100000000 25000000 int sum 29.692 3.37 5.89 0e+00 29.754 3.36 5.88 0e+00
100000000 25000000 int prod 30.733 3.25 5.69 0e+00 30.697 3.26 5.70 0e+00
100000000 25000000 int max 29.871 3.35 5.86 0e+00 29.700 3.37 5.89 0e+00
100000000 25000000 int min 29.809 3.35 5.87 0e+00 29.852 3.35 5.86 0e+00
100000000 50000000 half sum 28.590 3.50 6.12 1e-02 27.545 3.63 6.35 1e-02
100000000 50000000 half prod 27.416 3.65 6.38 1e-03 27.375 3.65 6.39 1e-03
100000000 50000000 half max 30.811 3.25 5.68 0e+00 30.670 3.26 5.71 0e+00
100000000 50000000 half min 30.818 3.24 5.68 0e+00 30.931 3.23 5.66 0e+00
100000000 25000000 float sum 29.719 3.36 5.89 1e-06 29.750 3.36 5.88 1e-06
100000000 25000000 float prod 29.741 3.36 5.88 1e-07 30.029 3.33 5.83 1e-07
100000000 25000000 float max 28.400 3.52 6.16 0e+00 28.400 3.52 6.16 0e+00
100000000 25000000 float min 28.364 3.53 6.17 0e+00 28.434 3.52 6.15 0e+00
100000000 12500000 double sum 33.989 2.94 5.15 0e+00 34.104 2.93 5.13 0e+00
100000000 12500000 double prod 33.895 2.95 5.16 2e-16 33.833 2.96 5.17 2e-16
100000000 12500000 double max 30.228 3.31 5.79 0e+00 30.273 3.30 5.78 0e+00
100000000 12500000 double min 30.324 3.30 5.77 0e+00 30.341 3.30 5.77 0e+00
100000000 12500000 int64 sum 29.914 3.34 5.85 0e+00 30.036 3.33 5.83 0e+00
100000000 12500000 int64 prod 30.975 3.23 5.65 0e+00 31.083 3.22 5.63 0e+00
100000000 12500000 int64 max 29.954 3.34 5.84 0e+00 29.949 3.34 5.84 0e+00
100000000 12500000 int64 min 29.946 3.34 5.84 0e+00 29.952 3.34 5.84 0e+00
100000000 12500000 uint64 sum 29.981 3.34 5.84 0e+00 30.100 3.32 5.81 0e+00
100000000 12500000 uint64 prod 30.911 3.24 5.66 0e+00 30.800 3.25 5.68 0e+00
100000000 12500000 uint64 max 29.890 3.35 5.85 0e+00 29.947 3.34 5.84 0e+00
100000000 12500000 uint64 min 29.929 3.34 5.85 0e+00 29.964 3.34 5.84 0e+00
Out of bounds values : 0 OK
Avg bus bandwidth : 5.81761
[Mpld3] Render Matplotlib chart to web using Mpld3
The following example is about rendering a matplotlib chart on web, which is based on Django framework to build up. I encountered some problems before, such as, not able to see chart on the web page or having a run-time error after reloading the page. But, all the problems are solved.
import numpy as np
import mpld3
def plot_test1(request):
context = {}
fig, ax = plt.subplots(subplot_kw=dict(axisbg='#EEEEEE'))
N = 100
"""
Demo about using matplotlib and mpld3 to rendor charts
"""
scatter = ax.scatter(np.random.normal(size=N),
np.random.normal(size=N),
c=np.random.random(size=N),
s=1000 * np.random.random(size=N),
alpha=0.3,
cmap=plt.cm.jet)
ax.grid(color='white', linestyle='solid')
ax.set_title("Scatter Plot (with tooltips!)", size=20)
labels = ['point {0}'.format(i + 1) for i in range(N)]
tooltip = mpld3.plugins.PointLabelTooltip(scatter, labels=labels)
mpld3.plugins.connect(fig, tooltip)
#figure = mpld3.fig_to_html(fig)
figure = json.dumps(mpld3.fig_to_dict(fig))
context.update({ 'figure' : figure })
"""
Demo about using tensorflow to predict the result
"""
num = np.random.randint(100)
prediction = predict_service.predict(num)
context.update({ 'num' : num })
context.update({ 'prediction' : prediction })
return render(request, 'demo/demo.html', context)
<script type="text/javascript" src="http://mpld3.github.io/js/mpld3.v0.2.js"></script>
<style>
/* Move down content because we have a fixed navbar that is 50px tall */
body {
padding-top: 50px;
padding-bottom: 20px;
}
</style>
<html>
<div id="fig01"></div>
<script type="text/javascript">
figure = {{ figure|safe }};
mpld3.draw_figure("fig01", figure);
</script>
</html>
So, we can see the result as follows:
<< demo/views.py>>
import matplotlib.pyplot as pltimport numpy as np
import mpld3
def plot_test1(request):
context = {}
fig, ax = plt.subplots(subplot_kw=dict(axisbg='#EEEEEE'))
N = 100
"""
Demo about using matplotlib and mpld3 to rendor charts
"""
scatter = ax.scatter(np.random.normal(size=N),
np.random.normal(size=N),
c=np.random.random(size=N),
s=1000 * np.random.random(size=N),
alpha=0.3,
cmap=plt.cm.jet)
ax.grid(color='white', linestyle='solid')
ax.set_title("Scatter Plot (with tooltips!)", size=20)
labels = ['point {0}'.format(i + 1) for i in range(N)]
tooltip = mpld3.plugins.PointLabelTooltip(scatter, labels=labels)
mpld3.plugins.connect(fig, tooltip)
#figure = mpld3.fig_to_html(fig)
figure = json.dumps(mpld3.fig_to_dict(fig))
context.update({ 'figure' : figure })
"""
Demo about using tensorflow to predict the result
"""
num = np.random.randint(100)
prediction = predict_service.predict(num)
context.update({ 'num' : num })
context.update({ 'prediction' : prediction })
return render(request, 'demo/demo.html', context)
<<demo/demo.html>>
<script type="text/javascript" src="http://d3js.org/d3.v3.min.js"></script><script type="text/javascript" src="http://mpld3.github.io/js/mpld3.v0.2.js"></script>
<style>
/* Move down content because we have a fixed navbar that is 50px tall */
body {
padding-top: 50px;
padding-bottom: 20px;
}
</style>
<html>
<div id="fig01"></div>
<script type="text/javascript">
figure = {{ figure|safe }};
mpld3.draw_figure("fig01", figure);
</script>
</html>
So, we can see the result as follows:
[Hadoop] To build a Hadoop environment (a single node cluster)
For the purpose of studying Hadoop, I have to build a testing environment to do. I found some resource links are good enough to build a single node cluster of Hadoop MapReduce as follows. And there are additional changes from my environment that I want to add some comments for my reference.
http://www.thebigdata.cn/Hadoop/15184.html
http://www.powerxing.com/install-hadoop/
$ sbin/start-yarn.sh
Finally, we can try the Hadoop MapReduce example as follows:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
http://www.thebigdata.cn/Hadoop/15184.html
http://www.powerxing.com/install-hadoop/
Login the user "hadoop"
$ sudo su - hadoopGo to the location of Hadoop
$ /usr/local/hadoopAdd the variables in ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HADOOP_HOME=/usr/local/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALLModify $JAVA_HOME in etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64Start dfs and yarn
$ sbin/start-dfs.sh$ sbin/start-yarn.sh
Finally, we can try the Hadoop MapReduce example as follows:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
[Spark] To install Spark environment based on Hadoop
This document is to record how to install Spark environment based on Hadoop as the previous one. For running Spark in Ubuntu machine, it should install Java first. Using the following command is easily to install Java in Ubuntu machine.
$ sudo apt-get install openjdk-7-jre openjdk-7-jdk
$ dpkg -L openjdk-7-jdk | grep '/bin/javac'
$ /usr/lib/jvm/java-7-openjdk-amd64/bin/javac
So, we can setup the JAVA_HOME environment variable as follows:
$ vim /etc/profile
append this ==> export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
$ sudo tar -zxf ~/Downloads/spark-1.6.0-bin-without-hadoop.tgz -C /usr/local/
$ cd /usr/local
$ sudo mv ./spark-1.6.0-bin-without-hadoop/ ./spark
$ sudo chown -R hadoop:hadoop ./spark
$ sudo apt-get update
$ sudo apt-get install scala
$ wget http://apache.stu.edu.tw/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
$ tar xvf spark-1.6.0-bin-hadoop2.6.tgz
$ cd /spark-1.6.0-bin-hadoop2.6/bin
$ ./spark-shell
$ cd /usr/local/spark
$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh
$ vim ./conf/spark-env.sh
append this ==> export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
$ sudo apt-get install openjdk-7-jre openjdk-7-jdk
$ dpkg -L openjdk-7-jdk | grep '/bin/javac'
$ /usr/lib/jvm/java-7-openjdk-amd64/bin/javac
So, we can setup the JAVA_HOME environment variable as follows:
$ vim /etc/profile
append this ==> export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
$ sudo tar -zxf ~/Downloads/spark-1.6.0-bin-without-hadoop.tgz -C /usr/local/
$ cd /usr/local
$ sudo mv ./spark-1.6.0-bin-without-hadoop/ ./spark
$ sudo chown -R hadoop:hadoop ./spark
$ sudo apt-get update
$ sudo apt-get install scala
$ wget http://apache.stu.edu.tw/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
$ tar xvf spark-1.6.0-bin-hadoop2.6.tgz
$ cd /spark-1.6.0-bin-hadoop2.6/bin
$ ./spark-shell
$ cd /usr/local/spark
$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh
$ vim ./conf/spark-env.sh
append this ==> export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
[picamera] Solving the problem of video display using Raspberry Pi Camera
When I tried to use Raspberry Pi Camera to display video or image, I encountered a problem that there is no image frame and the GUI showed a black frame on the screen. It took me a while to figure out this issue.
After searching the similar error on the Internet, I found it is related with using picamera library v1.11 and Python 2.7. So I try downgrading to picamera v1.10 and this should resolve the blank/black frame issue:
The linux command is as follows:
$ sudo pip uninstall picamera
$ sudo pip install 'picamera[array]'==1.10
So, it seems there are some issues with the most recent version of picamera that are causing a bunch of problems for Python 2.7 and Python 3 users.
After searching the similar error on the Internet, I found it is related with using picamera library v1.11 and Python 2.7. So I try downgrading to picamera v1.10 and this should resolve the blank/black frame issue:
The linux command is as follows:
$ sudo pip uninstall picamera
$ sudo pip install 'picamera[array]'==1.10
So, it seems there are some issues with the most recent version of picamera that are causing a bunch of problems for Python 2.7 and Python 3 users.
[Kafka] Install and setup Kafka
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.

Install and setup Kafka
$ sudo useradd kafka -m
$ sudo passwd kafka
$ sudo adduser kafka sudo
$ su - kafka
$ sudo apt-get install zookeeperd
To make sure that it is working, connect to it via Telnet:
$telnet localhost 2181
$ mkdir -p ~/Downloads
$ wget "http://mirror.cc.columbia.edu/pub/software/apache/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz" -O ~/Downloads/kafka.tgz
$ mkdir -p ~/kafka && cd ~/kafka
$ tar -xvzf ~/Downloads/kafka.tgz --strip 1
$ vi ~/kafka/config/server.properties
By default, Kafka doesn't allow you to delete topics. To be able to delete topics, add the following line at the end of the file:
⇒ delete.topic.enable = true
Start Kafka
$ nohup ~/kafka/bin/kafka-server-start.sh ~/kafka/config/server.properties > ~/kafka/kafka.log 2>&1 &
Publish the string "Hello, World" to a topic called TutorialTopic by typing in the following:
$ echo "Hello, World" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic
$ ~/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic TutorialTopic --from-beginning
Install and setup Kafka
$ sudo useradd kafka -m
$ sudo passwd kafka
$ sudo adduser kafka sudo
$ su - kafka
$ sudo apt-get install zookeeperd
To make sure that it is working, connect to it via Telnet:
$telnet localhost 2181
$ mkdir -p ~/Downloads
$ wget "http://mirror.cc.columbia.edu/pub/software/apache/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz" -O ~/Downloads/kafka.tgz
$ mkdir -p ~/kafka && cd ~/kafka
$ tar -xvzf ~/Downloads/kafka.tgz --strip 1
$ vi ~/kafka/config/server.properties
By default, Kafka doesn't allow you to delete topics. To be able to delete topics, add the following line at the end of the file:
⇒ delete.topic.enable = true
Start Kafka
$ nohup ~/kafka/bin/kafka-server-start.sh ~/kafka/config/server.properties > ~/kafka/kafka.log 2>&1 &
Publish the string "Hello, World" to a topic called TutorialTopic by typing in the following:
$ echo "Hello, World" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic
$ ~/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic TutorialTopic --from-beginning
[InfluxDB] Install and setup InfluxDB
Download the source and install
$ wget https://s3.amazonaws.com/influxdb/influxdb_0.12.1-1_amd64.deb$ sudo dpkg -i influxdb_0.12.1-1_amd64.deb
Edit influxdb.conf file
$ vim /etc/influxdb/influxdb.conf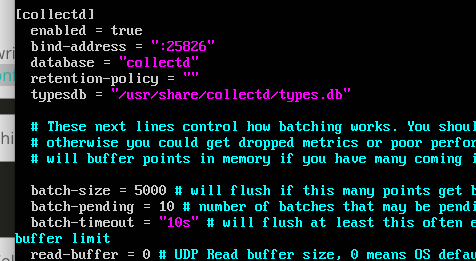
Restart influxDB
$ sudo service influxdb restartinfluxdb process was stopped [ OK ]
Starting the process influxdb [ OK ]
influxdb process was started [ OK ]
$ sudo netstat -naptu | grep LISTEN | grep influxd
tcp6 0 0 :::8083 :::* LISTEN 3558/influxd
tcp6 0 0 :::8086 :::* LISTEN 3558/influxd
tcp6 0 0 :::8088 :::* LISTEN 3558/influxd
Client command tool
$influx> show databases
Tuesday, May 9, 2017
[OpenGL] Draw 3D and Texture with BMP image using OpenGL Part I
It has been more than half of year not posting any article in my blogger and that makes me a little bit embarrassed. Well, for breaking this situation, I just quickly explain a simple concept about OpenGL coordinate.
Before taking an adventure to OpenGL, we have to know the coordinate in OpenGL first. Please check out the following graph. As we can see, the perspective of z position is pointed to us and it's so different from OpenCV.

If we take a look closer, the following OpenGL code can be explained in the picture below:
glBegin(GL_QUADS) # Start Drawing The Cube
# Front Face (note that the texture's corners have to match the quad's corners)
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, 1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f( 1.0, -1.0, 1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, 1.0, 1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f(-1.0, 1.0, 1.0) # Top Left Of The Texture and Quad
# Back Face
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, -1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f(-1.0, 1.0, -1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, 1.0, -1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f( 1.0, -1.0, -1.0) # Bottom Left Of The Texture and Quad
# Top Face
glTexCoord2f(0.0, 1.0); glVertex3f(-1.0, 1.0, -1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f(-1.0, 1.0, 1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 0.0); glVertex3f( 1.0, 1.0, 1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f( 1.0, 1.0, -1.0) # Top Right Of The Texture and Quad
# Bottom Face
glTexCoord2f(1.0, 1.0); glVertex3f(-1.0, -1.0, -1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, -1.0, -1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f( 1.0, -1.0, 1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, 1.0) # Bottom Right Of The Texture and Quad
# Right face
glTexCoord2f(1.0, 0.0); glVertex3f( 1.0, -1.0, -1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f( 1.0, 1.0, -1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, 1.0, 1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f( 1.0, -1.0, 1.0) # Bottom Left Of The Texture and Quad
# Left Face
glTexCoord2f(0.0, 0.0); glVertex3f(-1.0, -1.0, -1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, 1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f(-1.0, 1.0, 1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f(-1.0, 1.0, -1.0) # Top Left Of The Texture and Quad
glEnd(); # Done Drawing The Cube

So, right now, if we just look at the first section of the code as follows, it represents the blue quadrilateral for the front face.

And, the texture coordinate represents the direction of the image.

In sum, we can see the result just like this:


Before taking an adventure to OpenGL, we have to know the coordinate in OpenGL first. Please check out the following graph. As we can see, the perspective of z position is pointed to us and it's so different from OpenCV.

If we take a look closer, the following OpenGL code can be explained in the picture below:
glBegin(GL_QUADS) # Start Drawing The Cube
# Front Face (note that the texture's corners have to match the quad's corners)
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, 1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f( 1.0, -1.0, 1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, 1.0, 1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f(-1.0, 1.0, 1.0) # Top Left Of The Texture and Quad
# Back Face
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, -1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f(-1.0, 1.0, -1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, 1.0, -1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f( 1.0, -1.0, -1.0) # Bottom Left Of The Texture and Quad
# Top Face
glTexCoord2f(0.0, 1.0); glVertex3f(-1.0, 1.0, -1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f(-1.0, 1.0, 1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 0.0); glVertex3f( 1.0, 1.0, 1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f( 1.0, 1.0, -1.0) # Top Right Of The Texture and Quad
# Bottom Face
glTexCoord2f(1.0, 1.0); glVertex3f(-1.0, -1.0, -1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, -1.0, -1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f( 1.0, -1.0, 1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, 1.0) # Bottom Right Of The Texture and Quad
# Right face
glTexCoord2f(1.0, 0.0); glVertex3f( 1.0, -1.0, -1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f( 1.0, 1.0, -1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f( 1.0, 1.0, 1.0) # Top Left Of The Texture and Quad
glTexCoord2f(0.0, 0.0); glVertex3f( 1.0, -1.0, 1.0) # Bottom Left Of The Texture and Quad
# Left Face
glTexCoord2f(0.0, 0.0); glVertex3f(-1.0, -1.0, -1.0) # Bottom Left Of The Texture and Quad
glTexCoord2f(1.0, 0.0); glVertex3f(-1.0, -1.0, 1.0) # Bottom Right Of The Texture and Quad
glTexCoord2f(1.0, 1.0); glVertex3f(-1.0, 1.0, 1.0) # Top Right Of The Texture and Quad
glTexCoord2f(0.0, 1.0); glVertex3f(-1.0, 1.0, -1.0) # Top Left Of The Texture and Quad
glEnd(); # Done Drawing The Cube
So, right now, if we just look at the first section of the code as follows, it represents the blue quadrilateral for the front face.

And, the texture coordinate represents the direction of the image.

In sum, we can see the result just like this:
Tuesday, September 13, 2016
[Haar Classifier] Train your own OpenCV Haar classifier
I just keep a record for myself because there are a lot of documents teaching how to train your haar classifier and almost of them seem to don't work well. The following 2 items are clear and easy to understand.
The Data Image Source (cars) I use.
http://cogcomp.cs.illinois.edu/Data/Car/
1. Train your own OpenCV Haar classifier
https://github.com/mrnugget/opencv-haar-classifier-training
find ./positive_images -iname "*.pgm" > positives.txt
find ./negative_images -iname "*.pgm" > negatives.txt
perl bin/createsamples.pl positives.txt negatives.txt samples 550\
"opencv_createsamples -bgcolor 0 -bgthresh 0 -maxxangle 1.1\
-maxyangle 1.1 maxzangle 0.5 -maxidev 40 -w 48 -h 24"
python ./tools/mergevec.py -v samples/ -o samples.vec
opencv_traincascade -data classifier -vec samples.vec -bg negatives.txt\
-numStages 10 -minHitRate 0.999 -maxFalseAlarmRate 0.5 -numPos 1000\
-numNeg 600 -w 48 -h 24 -mode ALL -precalcValBufSize 1024\
-precalcIdxBufSize 1024
2. OpenCV Tutorial: Training your own detector | packtpub.com
https://www.youtube.com/watch?v=WEzm7L5zoZE
find pos/ -name '*.pgm' -exec echo \{\} 1 0 0 100 40 \; > cars.info
find neg/ -name '*.pgm' > bg.txt
opencv_createsamples -info cars.info -num 550 -w 48 -h 24 -vec cars.vec
opencv_createsamples -w 48 -h 24 -vec cars.vec
opencv_traincascade -data data -vec cars.vec -bg bg.txt \
-numPos 500 -numNeg 500 -numStages 10 -w 48 -h 24 -featureType LBP
P.S: Which one is best? I don't know...
The Data Image Source (cars) I use.
http://cogcomp.cs.illinois.edu/Data/Car/
1. Train your own OpenCV Haar classifier
https://github.com/mrnugget/opencv-haar-classifier-training
find ./positive_images -iname "*.pgm" > positives.txt
find ./negative_images -iname "*.pgm" > negatives.txt
perl bin/createsamples.pl positives.txt negatives.txt samples 550\
"opencv_createsamples -bgcolor 0 -bgthresh 0 -maxxangle 1.1\
-maxyangle 1.1 maxzangle 0.5 -maxidev 40 -w 48 -h 24"
python ./tools/mergevec.py -v samples/ -o samples.vec
opencv_traincascade -data classifier -vec samples.vec -bg negatives.txt\
-numStages 10 -minHitRate 0.999 -maxFalseAlarmRate 0.5 -numPos 1000\
-numNeg 600 -w 48 -h 24 -mode ALL -precalcValBufSize 1024\
-precalcIdxBufSize 1024
2. OpenCV Tutorial: Training your own detector | packtpub.com
https://www.youtube.com/watch?v=WEzm7L5zoZE
find pos/ -name '*.pgm' -exec echo \{\} 1 0 0 100 40 \; > cars.info
find neg/ -name '*.pgm' > bg.txt
opencv_createsamples -info cars.info -num 550 -w 48 -h 24 -vec cars.vec
opencv_createsamples -w 48 -h 24 -vec cars.vec
opencv_traincascade -data data -vec cars.vec -bg bg.txt \
-numPos 500 -numNeg 500 -numStages 10 -w 48 -h 24 -featureType LBP
P.S: Which one is best? I don't know...
[Image] How to resize, convert & modify images from the Linux
Installation
$ sudo apt-get install imagemagick
Converting Between Formats
$ convert howtogeek.png howtogeek.jpg
You can also specify a compression level for JPEG images:
$ convert howtogeek.png -quality 95 howtogeek.jpg
Resizing Images
$ convert example.png -resize 200×100 example.png
- to force the image to become a specific size – even if it messes up the aspect ratio
$ convert example.png -resize 200×100! example.png
$ convert example.png -resize 200 example.png
$ convert example.png -resize x100 example.png
Rotating an Image
convert howtogeek.jpg -rotate 90 howtogeek-rotated.jpg
Applying Effects
ImageMagick can apply a variety of effects to an image.
- For example, the following command applies the “charcoal” effect to an image:
$ convert howtogeek.jpg -charcoal 2 howtogeek-charcoal.jpg
- the “Implode” effect with a strength of 1:
# convert howtogeek.jpg -implode 1 howtogeek-imploded.jpg
Batch Processing
for file in *.png; do convert $file -rotate 90 rotated-$file; done
Reference:
http://www.howtogeek.com/109369/how-to-quickly-resize-convert-modify-images-from-the-linux-terminal/
$ sudo apt-get install imagemagick
Converting Between Formats
$ convert howtogeek.png howtogeek.jpg
You can also specify a compression level for JPEG images:
$ convert howtogeek.png -quality 95 howtogeek.jpg
Resizing Images
$ convert example.png -resize 200×100 example.png
- to force the image to become a specific size – even if it messes up the aspect ratio
$ convert example.png -resize 200×100! example.png
$ convert example.png -resize 200 example.png
$ convert example.png -resize x100 example.png
Rotating an Image
convert howtogeek.jpg -rotate 90 howtogeek-rotated.jpg
Applying Effects
ImageMagick can apply a variety of effects to an image.
- For example, the following command applies the “charcoal” effect to an image:
$ convert howtogeek.jpg -charcoal 2 howtogeek-charcoal.jpg
- the “Implode” effect with a strength of 1:
# convert howtogeek.jpg -implode 1 howtogeek-imploded.jpg
Batch Processing
for file in *.png; do convert $file -rotate 90 rotated-$file; done
Reference:
http://www.howtogeek.com/109369/how-to-quickly-resize-convert-modify-images-from-the-linux-terminal/
Thursday, September 8, 2016
[TensorFlow] My case to install TensorFlow with GPU enabled
My Operation System is Ubuntu 14.04 LTS 5 and GPU card is GeForce GTX 750Ti
1. Go to nvidia.com and download the driver (NVIDIA-Linux-x86_64-367.44.sh)
1. Go to nvidia.com and download the driver (NVIDIA-Linux-x86_64-367.44.sh)
2. For Nvidia to find linux header files (*):
$ sudo apt-get install build-essential linux-headers-$(uname -r)
3. To enable full screen text mode (nomodeset):
$ sudo gedit /etc/default/grub
>> Edit GRUB_CMDLINE_LINUX_DEFAULT="quiet splash nomodeset"
Save it and reboot
$ sudo update-grub
$ sudo reboot
4. Log into with Ctl +Alt + F1
5. Stop the X Server service
$ sudo service lightdm stop
6. Install nVidia driver
$ sudo ./NVIDIA-Linux-x86_64-367.44.sh
$ sudo apt-get install build-essential linux-headers-$(uname -r)
3. To enable full screen text mode (nomodeset):
$ sudo gedit /etc/default/grub
>> Edit GRUB_CMDLINE_LINUX_DEFAULT="quiet splash nomodeset"
Save it and reboot
$ sudo update-grub
$ sudo reboot
4. Log into with Ctl +Alt + F1
5. Stop the X Server service
$ sudo service lightdm stop
6. Install nVidia driver
$ sudo ./NVIDIA-Linux-x86_64-367.44.sh
7. Install CUDA (GPUs on Linux)
Download and install Cuda Toolkit
sudo dpkg -i cuda-repo-ubuntu1404-8-0-local_8.0.44-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda
8. Download and install cuDNN
tar xvzf cudnn-8.0-linux-x64-v5.1.tgz
cd cudasudo cp include/cudnn.h /usr/local/cuda-8.0/include
sudo cp lib64/* /usr/local/cuda-8.0/lib64
sudo chmod a+r /usr/local/cuda-8.0/lib64/libcudnn*
9. You also need to set the LD_LIBRARY_PATH and CUDA_HOME environment variables. Consider adding the commands below to your ~/.bash_profile. These assume your CUDA installation is in /usr/local/cuda:
$ vim ~/.bashrc
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-8.0/lib64"export CUDA_HOME=/usr/local/cuda-8.0
export PATH="$CUDA_HOME/bin:$PATH"
export PATH="$PATH:$HOME/bin"
10. To install TensorFlow for Ubuntu/Linux 64-bit, GPU enabled:
$ sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.10.1-cp27-none-linux_x86_64.whl
$ sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.10.1-cp27-none-linux_x86_64.whl
To find out which device is used, you can enable log device placement like this:
$ python
>>>> import tensorflow as tf
>>>> sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
$ python
>>>> import tensorflow as tf
>>>> sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
Tuesday, August 16, 2016
[OpenCV] To install OpenCV on Debian and create a test project using Netbeans
This document is the steps to install OpenCV on Debian and create a test project using Netbeans for my reference in case.
#Prepare the build environment GCC、Cmake、pkgconfig
#Install ImageI/O libraries
#Install Viode I/O libraries
#Install GTK+2.x and QT libraries
#Prepare the build environment GCC、Cmake、pkgconfig
$sudo apt-get -y install build-essential cmake pkg-config
#Install ImageI/O libraries
$sudo apt-get -y install libjpeg62-dev libtiff4-dev libjasper-dev
#Install Viode I/O libraries
$sudo apt-get -y install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$sudo apt-get -y install libdc1394-22-dev libxine2-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev
#Install GTK+2.x and QT libraries
$sudo apt-get -y install libgtk2.0-dev libqt4-dev
Thursday, August 11, 2016
[Hadoop] Setting up a Single Node Cluster
Basically these resource links are good enough to do a single node cluster of Hadoop MapReduce. But I still want to add some comments for my reference.
http://www.thebigdata.cn/Hadoop/15184.html
http://www.powerxing.com/install-hadoop/
Login the user "hadoop"
Go to the location of Hadoop
Add the variables in ~/.bashrc
Modify $JAVA_HOME in etc/hadoop/hadoop-env.sh
Start dfs and yarn
Finally, we can try the Hadoop MapReduce example as follows:
P.S:
In order to forcefully let the namenode leave safemode, following command should be executed:
http://www.thebigdata.cn/Hadoop/15184.html
http://www.powerxing.com/install-hadoop/
Login the user "hadoop"
# sudo su - hadoop
Go to the location of Hadoop
# /usr/local/hadoop
Add the variables in ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
Modify $JAVA_HOME in etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
Start dfs and yarn
# sbin/start-dfs.sh
# sbin/start-yarn.sh
Finally, we can try the Hadoop MapReduce example as follows:
# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
P.S:
In order to forcefully let the namenode leave safemode, following command should be executed:
# hdfs dfsadmin -safemode leave
Tuesday, August 2, 2016
[Tensorflow] Fizz-Buzz example enhancement
I am just based on this Fizz-Buzz example as below to add 2nd convolution layer and guess what? The result is quicker to be learn. But, this is just the first step to learn "Deep Learning"...
There is still a lot of things and knowledge that need to learn more.
http://joelgrus.com/2016/05/23/fizz-buzz-in-tensorflow/
Before

After

Reference
http://www.slideshare.net/WrangleConf/wrangle-2016-lightning-talk-fizzbuzz-in-tensorflow
There is still a lot of things and knowledge that need to learn more.
http://joelgrus.com/2016/05/23/fizz-buzz-in-tensorflow/
Before

After

Reference
http://www.slideshare.net/WrangleConf/wrangle-2016-lightning-talk-fizzbuzz-in-tensorflow
Monday, July 25, 2016
[Neutron] The first glance of L3HA mode in OpenStack Neutron ( Liberty version )
I just quickly take the first glance of L3HA mode in OpenStack Neutron ( Liberty version ) and is based on my tenant environment as follows:

# neutron net-list



Here I have 2 instances in my tenant:

So, if I use the instance: daanny_vm1 to ping danny_vm2, due to the different subnets, this action will trigger L3 vrouter function.
# ping 192.168.66.4 ( danny_vm2 )

# ip netns exec qrouter-f1e03fef-cccf-43de-9d35-56d11d636765 tcpdump -eln -i qr-4433f31f-5d icmp

The interface qr-4433f31f-5d is my subnet 192.168.44.0/24's gateway port as follows:


My tenant environment
# neutron router-list# neutron net-list

# neutron subnet-list

The Topology view looks like this:

Here I have 2 instances in my tenant:

So, if I use the instance: daanny_vm1 to ping danny_vm2, due to the different subnets, this action will trigger L3 vrouter function.
# ping 192.168.66.4 ( danny_vm2 )

# ip netns exec qrouter-f1e03fef-cccf-43de-9d35-56d11d636765 tcpdump -eln -i qr-4433f31f-5d icmp

The interface qr-4433f31f-5d is my subnet 192.168.44.0/24's gateway port as follows:
# neutron --os-tenant-name danny port-list | grep 4433f31f-5d
| 4433f31f-5d93-4fe4-868a-04ddcc38be20 | | fa:16:3e:25:22:b3 | {"subnet_id": "d169f180-4304-42f0-b11f-e094287bcd00", "ip_address": "192.168.44.1"} |
Keepalived related
L3HA mode is havily relied on the daemon: Keepalived and this daemon is existed in qrouter namespace.
# vi /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765/keepalived.conf
vrrp_instance VR_1 { state BACKUP interface ha-857640ad-a6 virtual_router_id 1 priority 50 garp_master_delay 60 nopreempt advert_int 2 track_interface { ha-857640ad-a6 } virtual_ipaddress { 169.254.0.1/24 dev ha-857640ad-a6 } virtual_ipaddress_excluded { 10.12.20.32/16 dev qg-f02984c6-dc 10.12.20.33/32 dev qg-f02984c6-dc 192.168.44.1/24 dev qr-4433f31f-5d 192.168.55.1/24 dev qr-16e20a36-fc 192.168.66.1/24 dev qr-35235c4f-64 fe80::f816:3eff:fe0d:2702/64 dev qr-16e20a36-fc scope link fe80::f816:3eff:fe25:22b3/64 dev qr-4433f31f-5d scope link fe80::f816:3eff:fe51:30a1/64 dev qg-f02984c6-dc scope link fe80::f816:3eff:fe8f:a85b/64 dev qr-35235c4f-64 scope link } virtual_routes { 0.0.0.0/0 via 10.12.0.254 dev qg-f02984c6-dc } }
There are other two files under /var/lib/neutron/ha_confs/<< qrouter uuid >>/
neutron-keepalived-state-change.log ==> log file
state ==> HA status
# find -L /proc/[1-9]*/task/*/ns/net -samefile /run/netns/qrouter-f1e03fef-cccf-43de-9d35-56d11d636765 | cut -d/ -f5
2276895
2276896
2277216
2277217
3284547
# ps aux | grep -e "2276895|2276896|2277216|2277217|3284547"
neutron 2276895 0.0 0.0 126160 41364 ? S Jul22 0:00 /usr/bin/python2.7 /usr/bin/neutron-keepalived-state-change --router_id=f1e03fef-cccf-43de-9d35-56d11d636765 --namespace=qrouter-f1e03fef-cccf-43de-9d35-56d11d636765 --conf_dir=/var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765 --monitor_interface=ha-857640ad-a6 --monitor_cidr=169.254.0.1/24 --pid_file=/var/lib/neutron/external/pids/f1e03fef-cccf-43de-9d35-56d11d636765.monitor.pid --state_path=/var/lib/neutron --user=119 --group=125
root 2276896 0.0 0.0 6696 756 ? S Jul22 0:00 ip -o monitor address
root 2277216 0.0 0.0 44752 856 ? Ss Jul22 0:13 keepalived -P -f /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765/keepalived.conf -p /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765.pid -r /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765.pid-vrrp
root 2277217 0.0 0.0 51148 1712 ? S Jul22 0:24 keepalived -P -f /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765/keepalived.conf -p /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765.pid -r /var/lib/neutron/ha_confs/f1e03fef-cccf-43de-9d35-56d11d636765.pid-vrrp
neutron 3284547 0.0 0.0 172176 36032 ? S Jul22 0:00 /usr/bin/python2.7 /usr/bin/neutron-ns-metadata-proxy --pid_file=/var/lib/neutron/external/pids/f1e03fef-cccf-43de-9d35-56d11d636765.pid --metadata_proxy_socket=/var/lib/neutron/metadata_proxy --router_id=f1e03fef-cccf-43de-9d35-56d11d636765 --state_path=/var/lib/neutron --metadata_port=8775 --metadata_proxy_user=119 --metadata_proxy_group=125 --verbose --log-file=neutron-ns-metadata-proxy-f1e03fef-cccf-43de-9d35-56d11d636765.log --log-dir=/var/log/neutron
# neutron l3-agent-list-hosting-router f1e03fef-cccf-43de-9d35-56d11d636765

Then, we learn that the master vrouter is in node-8.
There are other ways to know which node is master:
1. use the command to see if the interface qr-xxxxx and qg-xxxxx have ip address or not. If yes, this node is master.
- ip netns exec qrouter-f1e03fef-cccf-43de-9d35-56d11d636765 ip a
2. Check the following file that contains "master" or not.
- vim /var/lib/neutron/ha_confs/<< qrouter uuid >>/state
For more details:
http://www.slideshare.net/orimanabu/l3-ha-vrrp20141201

Friday, June 24, 2016
[Ceilometer] To survey how to improve the performance of OpenStack Ceilometer
Frankly speaking, OpenStack Ceilometer will suffer some kind of performance issues sooner or later if you don't modify or tune the configuration. The issues has two parts that need you to consider. One is the message bus and API loading, and the other is database. However, I find some best practices which are easy and quick for us to adopt. Here you go:
1. Telemetry(Ceilometer) best practices
a. Data collection
- Based on your needs, you can edit the pipeline.yaml configuration file to include a selected number of meters while disregarding the rest.
- By default, Telemetry service polls the service APIs every 10 minutes. You can change the polling interval on a per meter basis by editing the pipeline.yaml configuration file.
for example:
vim /etc/ceilometer/ceilometer.conf=> evaluation_interval=120vim /etc/ceilometer/pipeline.yaml=> interval: 120 - you can delay or adjust polling requests by enabling the jitter support. This adds a random delay on how the polling agents send requests to the service APIs. To enable jitter, set shuffle_time_before_polling_task in the ceilometer.conf configuration file to an integer greater than 0.
b. Data storage
- We recommend that you avoid open-ended queries.
- You can install the API behind mod_wsgi, as it provides more settings to tweak, likethreads and processes in case of WSGIDaemon. a. For more information on how to configure mod_wsgi, see the Telemetry Install Documentation.
- The collection service provided by the Telemetry project is not intended to be an archival service. Set a Time to Live (TTL) value to expire data and minimize the database size.
for example:
vi /etc/ceilometer/ceilometer.conf=> time_to_live=302400 - Use replica sets in MongoDB. Replica sets provide high availability through automatic failover. If your primary node fails, MongoDB will elect a secondary node to replace the primary node, and your cluster will remain functional.
- For more information on replica sets, see the MongoDB replica sets docs.
- Use sharding in MongoDB. Sharding helps in storing data records across multiple machines and is the MongoDB’s approach to meet the demands of data growth.
2. Metering Service (Ceilometer): Best Practices and Optimization
a. Modifying the List of Meters
sources:
- name: meter_source
interval: 604800
meters:
- "instance"
- "image"
- "image.size"
- "image.upload"
- "image.delete"
- "volume"
- "volume.size"
- "snapshot"
- "snapshot.size"
- "ip.floating"
- "network.*"
- "compute.instance.create.end"
- "compute.instance.delete.end"
- "compute.instance.update"
- "compute.instance.exists"
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://
b. Modifying the Polling Intervals
The interval attribute is the time between polls. Meters that are available as both notification and polling are going to be polled at the specified interval. To rely on notifications rather than polling, set the interval attribute to 604800 seconds, or once a week.
Reference



One of the main issues operators relayed was the polling that Ceilometer was running on Nova to gather instance information. It had a highly negative impact on the Nova API CPU usage, as it retrieves all the information about instances on regular intervals.
Subscribe to:
Comments (Atom)